Digging into the finer aspects of a site are important parts of technical SEO. One of the most important actions digital marketers can take to improve their technical search engine optimization (SEO) efforts is to use the correct meta tags and robot directives in their HTML code. One such tag that can easily improve the SEO value of a site is the noindex tag.
What are Meta Tags and Robot Directives for SEO?
To know what a noindex tag is, it’s important to first understand what tags and directives are and how they affect SEO.
Meta tags and robot directives both live in a site’s HTML code. Meta tags tell search engines about pages on a site to help them rank better for certain queries, boost a site’s authority, and generally give context for site content. Robot directives specifically tell web crawlers how to interact with a page, including whether a page should show up in search engine results pages (SERPs) at all.
Types of Tags & Directives
There are various types of meta tags and robot directives that tell search algorithms and web crawlers how to interact with a site, including:
- Noindex meta tag. A noindex directive tells web crawlers not to show a page in SERPs.
- Disallow meta tag. This tag tells search engine crawlers like Googlebot not to crawl a page.
- Nofollow tag. This tag tells search engines to ignore hyperlinks.
- Canonical tag. This tag tells search platforms what the “official” version of a piece of content is. For example, if a company has posted an article on its own blog and on another platform, this tag tells Google which version of the article should count for SEO purposes. In short, a canonical tag helps the company avoid duplicate content issues.

Noindex FAQs
What Does a Noindex Tag Do?
A noindex tag is a robot directive. That means it tells Google and other search engines how to interact with a website, including whether or not a page should be indexed or crawled.
A noindex tag, as the name implies, tells web crawlers like Googlebot not to index a webpage. This action means the noindexed page will not appear in organic SERPs. However, it will still be crawled and can be visited through links, site directories, and directly entering the specific page’s URL into a search bar.
How Does a Noindex Tag Affect SEO?
A properly utilized noindex tag can boost SEO efforts by blocking low-quality content from appearing in SERPs, which could tank site trust and domain authority.
When Should You Use a Disallow Tag?
A disallow tag is another directive that tells search engines how to interact with a page. Disallow tags specifically tell search engines not to crawl certain pages. This tag is important for helping companies save crawl budgets for more important pages.
When Should You Use a Nofollow Tag?
A nofollow tag is a directive telling search engines to ignore certain links and, on Google, to not go through PageRank, meaning the link does not pass any “SEO juice” or value to a site or page.
According to Google, “[u]se the nofollow value when other values don’t apply, and you’d rather Google not associate your site with, or crawl the linked page from, your site. For links within your own site, use the robots.txt disallow rule.”
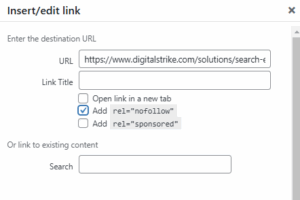
Adding this tag is simple on sites that run on WordPress.
To start, click on the hyperlink you want to tag in the WordPress backend. A gear entitled “Link options” should appear. Click the gear.
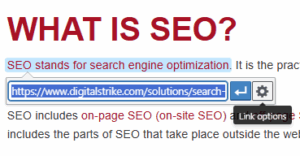
Next, click on the pencil icon that says “Edit.”
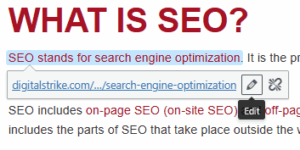
From there, a popup box should appear. Click the rel=”nofollow” box and then click “Update.”
When Should You Use a Noindex Meta Tag?
Use noindex tags for:
- Pages that are for user experience only, such as thank you pages or login pages;
- Pages that are not strictly for search engine optimization purposes, like landing pages, but that still need to be crawled and capitalized on for link equity;
- Low-quality content, to remove them from appearing in SERPs, which could negatively affect site ranking and authority; and
- /tag/ and /category/ pages.
Why Should You Use Noindex Tags for /tag/ and /category/ Pages?
Correctly categorizing all content on a site into the right buckets is critical for success. But not every page categorization needs to be indexed. /tag/ and /category/ pages, for example, should almost always have noindex tags.
The two primary reasons are to:
- Avoid content cannibalization. /tag/ and /category/ pages may have lots of duplicate content on them. This content might make sense to live on a site from a user experience perspective. From an SEO perspective, however, this content could count against sites in duplicate content-hating search algorithms. Switching to noindex tags for these specific pages could therefore help content from cannibalizing each other (competing against each other in search rankings) or penalizing a site for duplication.
- Make better use of the crawl budget. Crawlers have a lot of content to sift through, and each website has a limit (crawl budget) to how much time Google and other search engines spend crawling it. To make the use of a crawl budget, only the most valuable pages should be indexed; those pages do not include /tag/ or /category/ pages.
How Can You Check if a URL Has Noindex Status?
Digital marketers can check for noindex status with Google Search Console’s URL Inspection Tool or through the HTML code of individual pages.
How Can You Add a Noindex Tag to Your Webpage?
The failproof way to add a noindex tag to a webpage is to go directly to the page’s HTML source code and add rel=”noindex”. Using the URL Inspection Tool and inserting the webpage’s URL will ask Google to recrawl a page to update its index status.
Need assistance deciding which pages on your site need noindex tags? Contact the digital marketing experts at Digital Strike – Targeted Marketing.